 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediaClaw: Multimodal Intelligent-Agent Platform Technical Report
May 14, 2026MediaClaw is a multimodal agent platform built on the OpenClaw ecosystem. Its core design follows a three-layer architecture of unified abstraction, pluginized extension, and workflow orchestration. The system is intended to address practical deployment pain points in AIGC adoption, including fragmented capabilities, heterogeneous interfaces, disconnected production processes, and limited reuse of high-quality production workflows. \system{} abstracts full-category AIGC capabilities into a unified invocation model, uses plugins to support hot-pluggable capability expansion, and uses task-oriented Skills to turn complex production processes into reusable workflow assets. This report focuses on the architectural design philosophy of MediaClaw, the design logic of its core capability model, and the key engineering trade-offs in implementation. It aims to provide reusable practical reference for building multimodal capability platforms.
MotionRFT: Unified Reinforcement Fine-Tuning for Text-to-Motion Generation
Mar 28, 2026Text-to-motion generation has advanced with diffusion- and flow-based generative models, yet supervised pretraining remains insufficient to align models with high-level objectives such as semantic consistency, realism, and human preference. Existing post-training methods have key limitations: they (1) target a specific motion representation, such as joints, (2) optimize a particular aspect, such as text-motion alignment, and may compromise other factors; and (3) incur substantial computational overhead, data dependence, and coarse-grained optimization. We present a reinforcement fine-tuning framework that comprises a heterogeneous-representation, multi-dimensional reward model, MotionReward, and an efficient, fine-grained fine-tuning method, EasyTune. To obtain a unified semantics representation, MotionReward maps heterogeneous motions into a shared semantic space anchored by text, enabling multidimensional reward learning; Self-refinement Preference Learning further enhances semantics without additional annotations. For efficient and effective fine-tuning, we identify the recursive gradient dependence across denoising steps as the key bottleneck, and propose EasyTune, which optimizes step-wise rather than over the full trajectory, yielding dense, fine-grained, and memory-efficient updates. Extensive experiments validate the effectiveness of our framework, achieving FID 0.132 at 22.10 GB peak memory for MLD model and saving up to 15.22 GB over DRaFT. It reduces FID by 22.9% on joint-based ACMDM, and achieves a 12.6% R-Precision gain and 23.3% FID improvement on rotation-based HY Motion. Our project page with code is publicly available.
One-to-More: High-Fidelity Training-Free Anomaly Generation with Attention Control
Mar 18, 2026Industrial anomaly detection (AD) is characterized by an abundance of normal images but a scarcity of anomalous ones. Although numerous few-shot anomaly synthesis methods have been proposed to augment anomalous data for downstream AD tasks, most existing approaches require time-consuming training and struggle to learn distributions that are faithful to real anomalies, thereby restricting the efficacy of AD models trained on such data. To address these limitations, we propose a training-free few-shot anomaly generation method, namely O2MAG, which leverages the self-attention in One reference anomalous image to synthesize More realistic anomalies, supporting effective downstream anomaly detection. Specifically, O2MAG manipulates three parallel diffusion processes via self-attention grafting and incorporates the anomaly mask to mitigate foreground-background query confusion, synthesizing text-guided anomalies that closely adhere to real anomalous distributions. To bridge the semantic gap between the encoded anomaly text prompts and the true anomaly semantics, Anomaly-Guided Optimization is further introduced to align the synthesis process with the target anomalous distribution, steering the generation toward realistic and text-consistent anomalies. Moreover, to mitigate faint anomaly synthesis inside anomaly masks, Dual-Attention Enhancement is adopted during generation to reinforce both self- and cross-attention on masked regions. Extensive experiments validate the effectiveness of O2MAG, demonstrating its superior performance over prior state-of-the-art methods on downstream AD tasks.
MeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference
Jan 27, 2026We present MeanCache, a training-free caching framework for efficient Flow Matching inference. Existing caching methods reduce redundant computation but typically rely on instantaneous velocity information (e.g., feature caching), which often leads to severe trajectory deviations and error accumulation under high acceleration ratios. MeanCache introduces an average-velocity perspective: by leveraging cached Jacobian--vector products (JVP) to construct interval average velocities from instantaneous velocities, it effectively mitigates local error accumulation. To further improve cache timing and JVP reuse stability, we develop a trajectory-stability scheduling strategy as a practical tool, employing a Peak-Suppressed Shortest Path under budget constraints to determine the schedule. Experiments on FLUX.1, Qwen-Image, and HunyuanVideo demonstrate that MeanCache achieves 4.12X and 4.56X and 3.59X acceleration, respectively, while consistently outperforming state-of-the-art caching baselines in generation quality. We believe this simple yet effective approach provides a new perspective for Flow Matching inference and will inspire further exploration of stability-driven acceleration in commercial-scale generative models.
Lexicalized Constituency Parsing for Middle Dutch: Low-resource Training and Cross-Domain Generalization
Jan 11, 2026Recent years have seen growing interest in applying neural networks and contextualized word embeddings to the parsing of historical languages. However, most advances have focused on dependency parsing, while constituency parsing for low-resource historical languages like Middle Dutch has received little attention. In this paper, we adapt a transformer-based constituency parser to Middle Dutch, a highly heterogeneous and low-resource language, and investigate methods to improve both its in-domain and cross-domain performance. We show that joint training with higher-resource auxiliary languages increases F1 scores by up to 0.73, with the greatest gains achieved from languages that are geographically and temporally closer to Middle Dutch. We further evaluate strategies for leveraging newly annotated data from additional domains, finding that fine-tuning and data combination yield comparable improvements, and our neural parser consistently outperforms the currently used PCFG-based parser for Middle Dutch. We further explore feature-separation techniques for domain adaptation and demonstrate that a minimum threshold of approximately 200 examples per domain is needed to effectively enhance cross-domain performance.
OpenGround: Active Cognition-based Reasoning for Open-World 3D Visual Grounding
Dec 31, 20253D visual grounding aims to locate objects based on natural language descriptions in 3D scenes. Existing methods rely on a pre-defined Object Lookup Table (OLT) to query Visual Language Models (VLMs) for reasoning about object locations, which limits the applications in scenarios with undefined or unforeseen targets. To address this problem, we present OpenGround, a novel zero-shot framework for open-world 3D visual grounding. Central to OpenGround is the Active Cognition-based Reasoning (ACR) module, which is designed to overcome the fundamental limitation of pre-defined OLTs by progressively augmenting the cognitive scope of VLMs. The ACR module performs human-like perception of the target via a cognitive task chain and actively reasons about contextually relevant objects, thereby extending VLM cognition through a dynamically updated OLT. This allows OpenGround to function with both pre-defined and open-world categories. We also propose a new dataset named OpenTarget, which contains over 7000 object-description pairs to evaluate our method in open-world scenarios. Extensive experiments demonstrate that OpenGround achieves competitive performance on Nr3D, state-of-the-art on ScanRefer, and delivers a substantial 17.6% improvement on OpenTarget. Project Page at https://why-102.github.io/openground.io/.
HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity in Vision-Language Alignment
Nov 10, 2025Contrastive vision-language models like CLIP have achieved impressive results in image-text retrieval by aligning image and text representations in a shared embedding space. However, these models often treat text as flat sequences, limiting their ability to handle complex, compositional, and long-form descriptions. In particular, they fail to capture two essential properties of language: semantic hierarchy, which reflects the multi-level compositional structure of text, and semantic monotonicity, where richer descriptions should result in stronger alignment with visual content.To address these limitations, we propose HiMo-CLIP, a representation-level framework that enhances CLIP-style models without modifying the encoder architecture. HiMo-CLIP introduces two key components: a hierarchical decomposition (HiDe) module that extracts latent semantic components from long-form text via in-batch PCA, enabling flexible, batch-aware alignment across different semantic granularities, and a monotonicity-aware contrastive loss (MoLo) that jointly aligns global and component-level representations, encouraging the model to internalize semantic ordering and alignment strength as a function of textual completeness.These components work in concert to produce structured, cognitively-aligned cross-modal representations. Experiments on multiple image-text retrieval benchmarks show that HiMo-CLIP consistently outperforms strong baselines, particularly under long or compositional descriptions. The code is available at https://github.com/UnicomAI/HiMo-CLIP.
* Accepted by AAAI 2026 as an Oral Presentation (13 pages, 7 figures, 7 tables)
Foundation Model for Skeleton-Based Human Action Understanding
Aug 18, 2025Human action understanding serves as a foundational pillar in the field of intelligent motion perception. Skeletons serve as a modality- and device-agnostic representation for human modeling, and skeleton-based action understanding has potential applications in humanoid robot control and interaction. \RED{However, existing works often lack the scalability and generalization required to handle diverse action understanding tasks. There is no skeleton foundation model that can be adapted to a wide range of action understanding tasks}. This paper presents a Unified Skeleton-based Dense Representation Learning (USDRL) framework, which serves as a foundational model for skeleton-based human action understanding. USDRL consists of a Transformer-based Dense Spatio-Temporal Encoder (DSTE), Multi-Grained Feature Decorrelation (MG-FD), and Multi-Perspective Consistency Training (MPCT). The DSTE module adopts two parallel streams to learn temporal dynamic and spatial structure features. The MG-FD module collaboratively performs feature decorrelation across temporal, spatial, and instance domains to reduce dimensional redundancy and enhance information extraction. The MPCT module employs both multi-view and multi-modal self-supervised consistency training. The former enhances the learning of high-level semantics and mitigates the impact of low-level discrepancies, while the latter effectively facilitates the learning of informative multimodal features. We perform extensive experiments on 25 benchmarks across across 9 skeleton-based action understanding tasks, covering coarse prediction, dense prediction, and transferred prediction. Our approach significantly outperforms the current state-of-the-art methods. We hope that this work would broaden the scope of research in skeleton-based action understanding and encourage more attention to dense prediction tasks.
LAD-Reasoner: Tiny Multimodal Models are Good Reasoners for Logical Anomaly Detection
Apr 17, 2025Recent advances in industrial anomaly detection have highlighted the need for deeper logical anomaly analysis, where unexpected relationships among objects, counts, and spatial configurations must be identified and explained. Existing approaches often rely on large-scale external reasoning modules or elaborate pipeline designs, hindering practical deployment and interpretability. To address these limitations, we introduce a new task, Reasoning Logical Anomaly Detection (RLAD), which extends traditional anomaly detection by incorporating logical reasoning. We propose a new framework, LAD-Reasoner, a customized tiny multimodal language model built on Qwen2.5-VL 3B. Our approach leverages a two-stage training paradigm that first employs Supervised Fine-Tuning (SFT) for fine-grained visual understanding, followed by Group Relative Policy Optimization (GRPO) to refine logical anomaly detection and enforce coherent, human-readable reasoning. Crucially, reward signals are derived from both the detection accuracy and the structural quality of the outputs, obviating the need for building chain of thought (CoT) reasoning data. Experiments on the MVTec LOCO AD dataset show that LAD-Reasoner, though significantly smaller, matches the performance of Qwen2.5-VL-72B in accuracy and F1 score, and further excels in producing concise and interpretable rationales. This unified design reduces reliance on large models and complex pipelines, while offering transparent and interpretable insights into logical anomaly detection. Code and data will be released.
Deep Learning-Powered Electrical Brain Signals Analysis: Advancing Neurological Diagnostics
Feb 24, 2025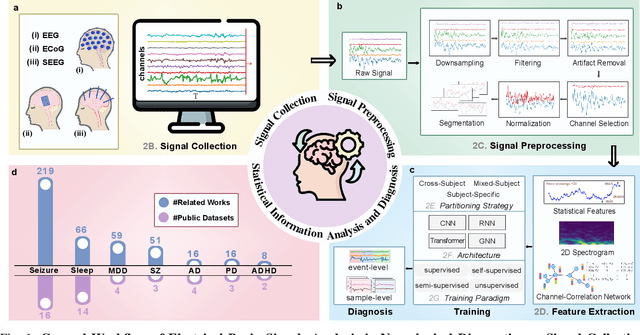
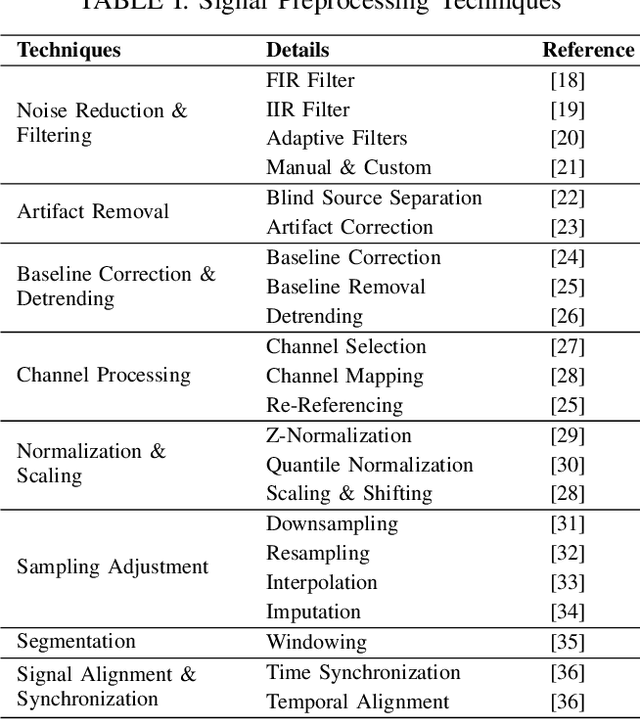

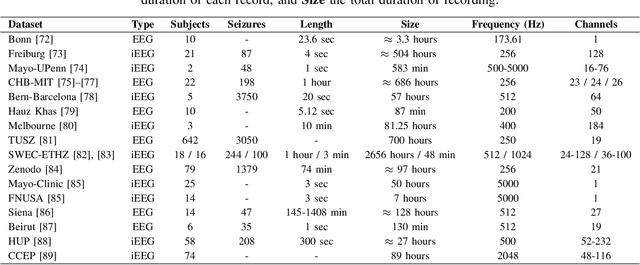
Neurological disorders represent significant global health challenges, driving the advancement of brain signal analysis methods. Scalp electroencephalography (EEG) and intracranial electroencephalography (iEEG) are widely used to diagnose and monitor neurological conditions. However, dataset heterogeneity and task variations pose challenges in developing robust deep learning solutions. This review systematically examines recent advances in deep learning approaches for EEG/iEEG-based neurological diagnostics, focusing on applications across 7 neurological conditions using 46 datasets. We explore trends in data utilization, model design, and task-specific adaptations, highlighting the importance of pre-trained multi-task models for scalable, generalizable solutions. To advance research, we propose a standardized benchmark for evaluating models across diverse datasets to enhance reproducibility. This survey emphasizes how recent innovations can transform neurological diagnostics and enable the development of intelligent, adaptable healthcare solutions.